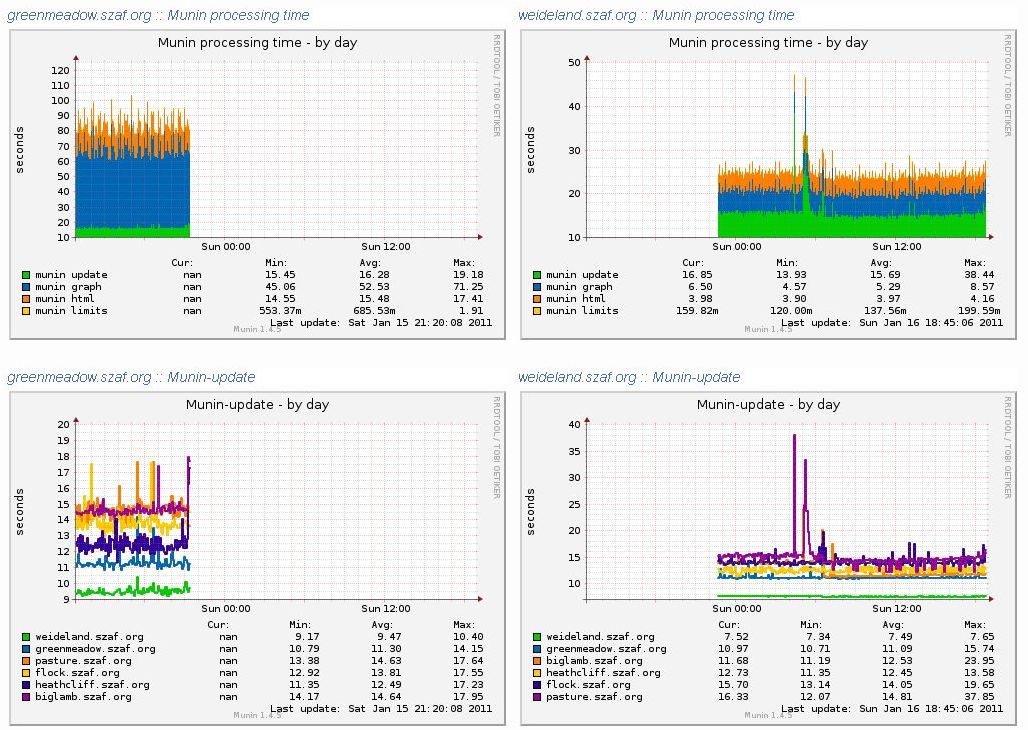
Gestern schrieb ich schon, daß ich mal wieder wahrlich zu nichts komme (jedenfalls nicht zu den Sachen, die ich mir vorgenommen hatte) - daher mußte bislang auch die Einrichtung des neuen Rechners (die ich eigentlich in der ersten Woche des neuen Jahres abzuschließen hoffte) zurückstehen. Heute habe ich damit aber dann einmal - mit Unterstützung aus dem IRC - angefangen und ein Debian Squeeze (dessen Release ja unmittelbar bevorsteht) installiert. Da die Maschine per KVM-Switch an Monitor, Tastatur und Maus hängt, habe ich mich mittlerweile entschlossen, sie nicht nur als Server, sondern auch als Desktop zu nutzen, auch um einmal ein Gefühl dafür zu bekommen, wie sich ein Linux auf dem Desktop so anfühlt - denn obschon ich seit gut 10 Jahren mit Linux als Server-OS umgehen, arbeite ich auf dem Desktop immer noch unter Windows (zunehmend ergänzt um Tools aus der unixoiden Welt).
Aufgrund meiner bisher mangelnden Erfahrung mit der Installation eines Systems (ich kenne den Arbeitsgang in der Regel erst beginnend mit der Anpassung eines vom Provider aufgespielten Images und habe Erfahrung im wesentlichen mit dem Zugang via SSH, nicht mit der Arbeit an der Konsole …) und der Tatsache, daß Debian für das bevorstehende Release alle nicht-freie Firmware aus dem main-Archiv entfernt hat, befürchtete ich erhebliche Probleme, schließlich sind mir aus den vorgenannten Gründen im weitesten Sinne hardwarenahe Arbeiten (Treiber, Kernel, Partitionierung von Platten, Auswahl des Filesystems und Einrichtung von RAID, LVM und Co.) nicht wirklich vertraut. Der Ablauf erwies sich aber als angenehm einfach.
Nach dem Herunterladen eines Netinstall-Images aus den täglichen Snapshots und dessen Brennen auf CD wurde mir nach dem Boot angeboten, den graphischen oder den konsolenorientierten Installer zu starten, wobei ich mich für letzteres entschied; danach wurde ich durch die Ersteinrichtung geführt, bis … tatsächlich eine fehlende Firmware (rtl8168d-1.fw) gefunden wurde, sinnigerweise ausgerechnet für die (Realtek-)Netzwerkkarte (ohne die sich ein Netinstall dann vermutlich nicht so richtig erfolgreich gestalten dürfte). Glücklicherweise hatte ich mich bereits vorher informiert, wo Debian die nicht-freie Firmware jetzt versteckt hat, so daß ich den entsprechen Tarball herunterladen und via USB-Stick bereitstellen konnte. Das half aber nicht; weder der Tarball noch die ausgepackten Debs konnten den Installer glücklich machen. Weitere Suche mit dem Namen der vermißten Firmware führte dann zu einem Bugreport und dem entsprechenden Firmware-Paket mit Realtek-Firmware; ich habe dann entsprechend das dort verlinkte Tar-Archiv heruntergeladen, ausgepackt und - nach mehreren erfolglosen Versuchen - die Realtek-Firmware in das Root-Verzeichnis des USB-Sticks gepackt. Jetzt war der Installer glücklich.
Im weiteren Verlauf gelang es mir allerdings dennoch nicht, eine Netzwerkverbindung aufzubauen, was die weitere Installation etwas hinderte, insbesondere soweit Repositories eingebunden und Sicherheitsupdates geladen werden sollte; nach deren Abschluss und einem Reboot war jedoch eine Netzwerkverbindung vorhanden. Hilfreich für den absoluten Anfänger *hüstel* ist es übrigens in solchen Fällen zu wissen, daß man mit Alt-4 ein Terminal mit den Logs und Fehlermeldungen angezeigt bekommt, mit Alt-1 wieder zurückkomt und ggf. auf einem der anderen TTYs eine Shell starten kann. Dokumentiert ist das im Install-Manual.
[Update vom 23.01.2011: Offenbar handelt es sich bei dem Problem mit der Firmware für die Realtek-Netzwerkkarte noch um einen Bug, der mit dem ersten Point-Release behoben werden soll - sowohl hinsichtlich der Probleme des Installers, die Firmware auf dem USB-Stick zu finden, als auch hinsichtlich der fehlenden Netzwerkkonnektivität nach dem Finden der Firmware.]
Der Rest der Installation bis zum ersten Reboot verlief ereignislos, gut unterstützt und dokumentiert - es gelang mir auch auf Anhieb (naja, mit einigen Versuchen), aus meinen beiden Festplatten ein RAID 1 (mit gesonderter Bootpartition) zu erstellen, darüber LVM zu legen, die einzelnen Logical Volumes anzulegen und zu formatieren, ohne daß ich (abgesehen von Hinweisen zu der grundsätzlichen Auswahl des Filesystems und der Partitionierung) irgendeine Unterstützung via IRC gebraucht hätte.
"Installation von Debian Squeeze" vollständig lesen
 Aber jetzt kann ich immerhin beruhigt festhalten, daß das Problem nicht bei der häuslichen Einwahltechnik lag - und das ganze Debugging für die Katz war.
Aber jetzt kann ich immerhin beruhigt festhalten, daß das Problem nicht bei der häuslichen Einwahltechnik lag - und das ganze Debugging für die Katz war. 
 ), und nach einigen kleineren Schwierigkeiten *räusper* war dann auch technisch und organisatorisch alles im grünen Bereich. Einziges Manko: Die nach der Online-Verfügbarkeitsprüfung angeblich bereitstehende 16.000er-Anbindung konnte man nicht schalten - aber 6.000 ist ja immer noch mehr als 2.000.
), und nach einigen kleineren Schwierigkeiten *räusper* war dann auch technisch und organisatorisch alles im grünen Bereich. Einziges Manko: Die nach der Online-Verfügbarkeitsprüfung angeblich bereitstehende 16.000er-Anbindung konnte man nicht schalten - aber 6.000 ist ja immer noch mehr als 2.000.