Dieses Wochenende war Valentinstag, und dem Anlaß angemessen habe ich für uns ein (Heim-)Kinoprogramm mit Stieg Larsson organisiert: für Samstag stand "Verblendung" als Teil 1 der Millenium-Trilogie auf dem Programm, zu absolvieren per DVD auf der heimischen Fernseh-Couch, am heutigen Sonntag schloß sich dann ein Besuch im UFA-Kino für "Verdammnis" an, der eigentlich von einem gemeinsamen Abendessen gefolgt sein sollte. Der samstägliche Part funktionierte auch gut, aber der Kinobesuch heute! Lieber Himmel.
Unser "heimisches" Kino hatte den Film dummerweise nach nur einer Woche (!) schon wieder abgesetzt, daher mußte das UFA ran (in dem ich bisher noch nicht war); praktischerweise konnte man die Karten direkt übers Internet buchen und ausdrucken. Den ausgedruckten Wisch sollte man dann im Kino vor einen Automaten halten, der die Karten produziert; einfach und übersichtlich, sollte man denken. Nur war dem nicht so.
Es ging schon damit los, daß wir bereits in der Anfahrt in einem längeren Stau standen; wer kommt auch auf die Idee, die Einfahrt zum Parkhaus neben dem Kino wie auch dessen Ausfahrt so zu legen, daß der komplette Fußgängerverkehr von und zum Kino sie kreuzt?! Und dazu noch an zwei Stellen? Nachdem wir unter Verbrauch eines Großteils der Pufferzeit dieses Problem gemeistert hatten, standen wir dann komplett fassungslos am Ende der Eingangshalle. Die war nämlich voll. Voller Menschen. Und man war nicht in der Lage, einzelne Warteschlangen für die Kassen, die Info-Theke und den Zugang zu den Kinos abzutrennen, so daß niemand so recht wußte, wer wo hin wollte. Glücklicherweise mußten wir unsere Karten ja nur noch ausdrucken, und nach etwas Orientierungslosigkeit fiel ein Transparent auf, daß auf den entsprechenden Automaten an der Seite "neben dem Aufzug" verwies. Dort angelangt stellte sich allerdings heraus, daß dieser derzeit nicht betriebsbereit war. 
Nun war guter Rat teuer. Wir stellten uns mal "in Richtung" Infopoint an, kamen aber nicht so recht voran … Glücklicherweise bemerkte ich etliche Zeit später, daß offenbar jemand den Automaten wieder instandgesetzt hatte, eilte dorthin, druckte erfolgreich unsere Karten aus, und dann stürmten wir in aller Eile - unter Verzicht auf Popcorn, Getränke und sonst etwas - aufs Ziel los und kamen sogar noch rechtzeitig.
Kurz und gut: die Filme waren beide sehr gut - ich kann sie nur empfehlen, wenn sie auch, wie ich hörte, die Bücher stark verkürzen! -, aber dieses Kino wird uns nicht wiedersehen, wenn ich es vermeiden kann. (Den Versuch, das im selben Komplex befindliche Restaurant zu frequentieren, von dem man aus den letzten Monaten online ohnehin nur furchtbare Verrisse lesen konnte, haben wir nach einem Blick hinein dann auch abgebrochen; dort sah es ähnlich chaotisch aus. Dann lieber auf dem Heimweg eine Pizza mitnehmen.)

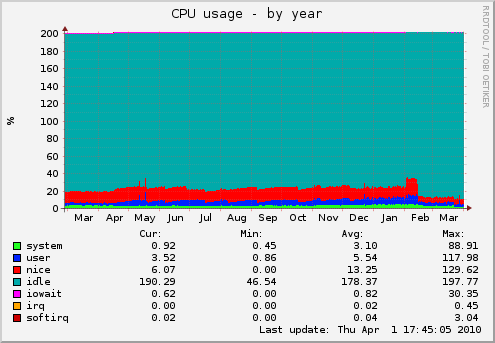
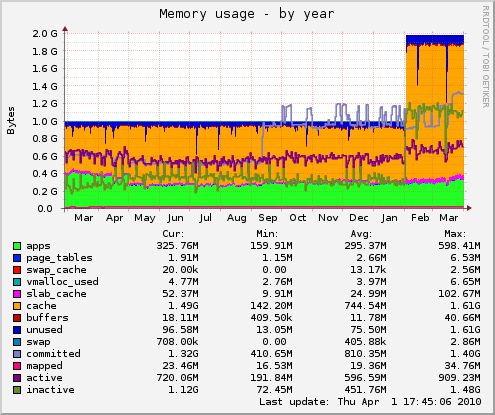
 ). Insgesamt empfinde ich 10 Tage für die Bearbeitung meiner Abrechnungen bei zwei verschiedenen Stellen einschließlich der Überweisung mehrerer tausend Euro als ausgesprochen schnell. Da könnte sich die eine oder andere Behörde, Firma oder Institution eine Scheibe von abschneiden.
). Insgesamt empfinde ich 10 Tage für die Bearbeitung meiner Abrechnungen bei zwei verschiedenen Stellen einschließlich der Überweisung mehrerer tausend Euro als ausgesprochen schnell. Da könnte sich die eine oder andere Behörde, Firma oder Institution eine Scheibe von abschneiden.